MENU
En el episodio de hoy de Un podcast ninja sobre Big Data os voy a contar cómo funciona Sora, un modelo de Inteligencia Artificial de OpenAI que genera videos a partir de textos.
A grandes rasgos Sora es un modelo generativo cuyo objetivo es generar vídeos a partir de instrucciones de texto.
Si os preguntáis cuándo estará disponible Sora o cómo probar Sora que sepáis que va a tocar esperar.
OpenAI está en las etapas finales de desarrollo de Sora y aún está tomando medidas de seguridad esenciales antes de hacerla accesible al público.
La idea es evitar la desinformación, el contenido de odio y los sesgos por lo que en OpenAI están comprometidos en asegurar que Sora sea lanzado de manera responsable.
Por tanto, la fecha de lanzamiento de Sora aún no ha sido anunciada oficialmente.
OpenAI ha confirmado que Sora sigue siendo un proyecto de investigación y, por el momento, no está disponible para el público.
Los únicos con acceso temprano a Sora, más allá de los desarrolladores de OpenAI, son un grupo reducido de artistas visuales, diseñadores y cineastas con el objetivo de recopilar feedback y optimizar el modelo para profesionales creativos. O
No hay lista de espera ni una fecha de lanzamiento estimada.
Así que par saber "¿cuándo sale Sora?" o "¿cómo probar Sora?", manteneos informados a través de las actualizaciones de OpenAI.
Para entrenar un modelo como Sora, que genere vídeo a partir de instrucciones de texto, lo primero que necesitamos son muchos vídeos con sus correspondientes descripciones.
Y hacen falta descripciones súper precisas.
Cuanto más precisa y detallada es la descripción del vídeo en el conjunto de entrenamiento de Sora, más capaz será el modelo de generar un vídeo ajustado al prompt que le pase el usuario.
Lo que pasa es que no hay muchos vídeos con descripciones hiper precisas y detalladas así que, aquí tenemos el segundo modelo de Machine Learning que hace falta.
Uno que genera descripciones detalladas y precisas.
Esto lo que hace básicamente es aumentar la calidad de los datos de entrenamiento del modelo.
Mejores datos de entrenamiento resulta en un modelo mejor.
Esta es la regla número 1 del Machine Learning, así en general.
Así que tenemos en el conjunto de entrenamiento vídeos con sus correspondientes descripciones detalladas y precisas.
Un vídeo es una estructura de datos compleja.
Cada fotograma es una imagen de unas dimensiones determinadas.
Imaginad que es un vídeo HD, en alta resolución, lo que significa que es una imagen de 1280 píxeles de ancho y 720 píxeles de alto, es decir, casi 1 millón de píxeles.
Si además, el vídeo es en color serían además fotogramas con componentes de rojo, de verde y de azul que superpuestas resultan en el fotograma de color que vemos.
O sea, que tenemos casi 1 millón de píxeles por cada componente de color lo que resulta en casi 3 millones de píxeles.
Por cada fotograma.
Esto es bastante cantidad de información a mover si queremos llegar a entrenar una red neuronal porque además necesitaremos del orden de decenas o centenas de miles de vídeos en el dataset de entrenamiento.
Así que una parte fundamental es codificar los vídeos y, en este caso, los transforman en parches espacio-temporales.
Estos parches espacio-temporales no son más que una representación de la información visual.
Las personas entendemos los vídeos como una secuencia de imágenes en el tiempo.
Bien.
Pues la idea es encontrar una representación de los vídeos que pueda entender el modelo y que esté más comprimida para que sea más manejable a la hora de entrenar a Sora.
Es como si vais un fin de semana a Paris y os queréis llevar un recuerdo de vuestra visita a la torre Eiffel.
No se os ocurriría construir una maqueta en 3 dimensiones para mantener todos los detalles del momento ya que tardaríais un montón y cuesta mucho esfuerzo.
Sacáis una foto y seguís con vuestras vidas.
La foto no es en 3 dimensiones así que perdéis un poco de información peeeero es lo suficientemente buena para recordar el momento y más eficiente que una maqueta en 3D.
Pues esto es parecido.
Aquí tenemos un nuevo modelo de Machine Learning, una red neuronal que transforma un vídeo en una representación comprimida tanto temporal como espacialmente.
Igual para nosotros, simples humanos, esa representación no nos parece más que números sin sentido peero ahí está el vídeo y ya se podría utilizar para entrenar a Sora.
De estas representaciones comprimidas de los vídeos se extraen parches espacio-temporales y esto sí, es lo que se utiliza para entrenar a Sora junto a las descripciones ultradetalladas de antes.
Sora es un modelo de difusión un poco especial.
Los modelos de difusión son redes neuronales que se entrenan para predecir ruido.
Imaginad que tenemos un conjunto de imágenes de entrenamiento.
A cada imágen le añadimos ruido.
Una vez que el modelo predice el ruido, le pasamos el ruido de verdad y a partir del error que ha cometido entre su predicción y la realidad va ajustando sus coeficientes.

Este proceso de entrenamiento se va repitiendo con varias imágenes del conjunto de entrenamiento y varios ruidos generados hasta que el modelo llega a predecir el ruido de una manera pues bastante precisa.
Vale.
Tenemos el modelo de difusión entrenado.
Y entonces, lo usamos al revés, le pasamos una imagen con sólo ruido.
El modelo no sabe que le hemos pasado sólo ruido ya que siempre le hemos pasado una imagen a la que hemos añadido ruido.
Pero predice el ruido igual.
Si de manera iterativa vamos substrayendo la predicción del modelo de difusión de nuestro ruido original acabamos teniendo una imagen nueva generada.
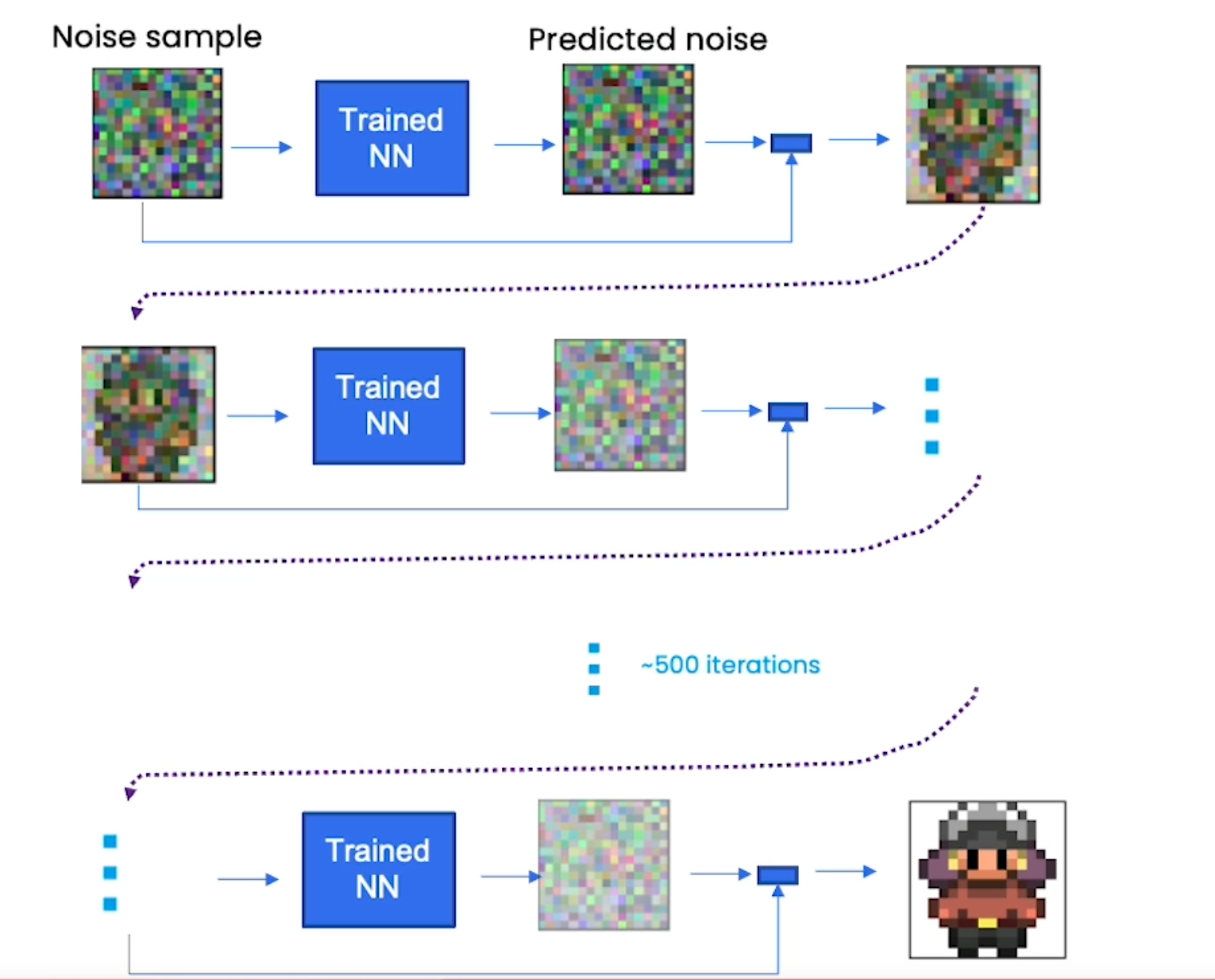
Es decir, generamos un ruido y se lo pasamos al modelo de difusión.
El modelo de difusión nos da una predicción del ruido y se lo substraemos a nuestro ruido original.
El resultado se lo volvemos a pasar al modelo que nos da otra predicción, volvemos a substraer esta predicción y se lo volvemos a pasar.
Pues al final, así es como se genera una imagen completamente nueva.
Con un pero que no os he contado, pero que os cuento ahora.
También hay que añadirle la descripción de la imagen tanto en el entrenamiento como a la hora de usar el modelo de difusión.
En el este segundo caso lo que añadiríamos sería la instrucción de lo que queremos que genere, lo que viene siendo el prompt.
Históricamente la arquitectura de la red neuronal en modelos de difusión era una arquitectura llamada U-Net, que es un tipo de red neuronal convolucional.
En Sora en vez de esta arquitectura U-Net se utiliza la arquitectura de transformer.
Sora es un modelo de tipo diffusion transformer.
La arquitectura transformer se diseñó para utilizarse con secuencias de datos, en concreto para textos, que son secuencias de palabras.
De hecho es lo que ha supuesto el avance brutal de los modelos del lenguaje.
En el caso de Sora se utiliza para vídeos que no dejan de ser secuencias de imágenes.
Funcionan con dos ideas clave:
Primero, la idea de que la red neuronal sea capaz de enfocarse en partes específicas de la entrada.
Por ejemplo, cuando un Transformer procesa un texto, no trata todas las palabras por igual.
Algunas palabras son más importantes para entender el significado completo.
El Transformer asigna un "peso" o importancia a cada palabra de la oración. Es decir, que las palabras más relevantes para el significado general reciben pesos más altos.
Es como si el Transformer "subrayara" las partes más importantes de la oración para no olvidarlas.
Luego, el Transformer combina todas estas palabras ponderadas para formar una representación concentrada de la oración. Esta representación captura no solo las palabras en sí sino también cómo se relacionan entre sí dentro de la oración.
Por otro lado, permite el procesamiento en paralelo.
En vez de procesar palabra por palabra, en el caso de textos, los Transformers pueden considerar todas las palabras de una vez lo que los hace mucho más rápidos a la hora de aprender de grandes cantidades de datos secuenciales como textos o vídeos.
Lo guay de la arquitectura de transformer y que también se ha comprobado con Sora, es que escala muy bien, es decir que los resultados mejoran mucho a medida que se aumenta la cantidad de cálculo durante el entrenamiento del modelo.
Cuanto más se "entrena" un modelo con más parámetros, datasets de entrenamiento más grandes y durante más tiempo, mejor se vuelve en la generación de videos.
Con Sora, OpenAI ha demostrado los resultados de escalar modelos de difusión basados en una arquitectura de transformer.
Espero que el episodio de hoy os sea de provecho y que aprendáis algo de valor.
Si es así, no olvidéis dejar una valoración de 5 estrellas del podcast en Apple podcasts, en Spotify, en Ivoox o donde quiera que escuchéis el podcast.
Recordad que si tenéis cualquier duda o pregunta podéis contactar conmigo a través del formulario de contacto o podemos seguir la conversación en Twitter.
Muchas gracias por estar ahí y os espero en el próximo episodio de Un Podcast Ninja sobre Big Data.