La sabiduría del universo está en Internet.
Y en el campo de la Inteligencia Artificial y el Aprendizaje Automático no iba a ser de otra manera.
Podrías empezar a hacer cursos de Machine Learning en Internet hoy y dedicar el resto de horas de tu vida a hacer cursos y más cursos (incluso las horas que se supone deberías usar para dormir).
Cursos de todos los niveles, precios y duraciones.
Sin embargo, hay un curso de Machine Learning que casi siempre sale en la lista de elegidos.
El curso de Machine Learning de la Universidad de Stanford en Coursera.
El curso de Machine Learning de la Universidad de Stanford
Este curso fue publicado por primera vez en 2011 y se trata de una versión simplificada del curso CS229 que ofrece Stanford como introducción al aprendizaje automático.
Menos matemáticas y menos temario.
Sin embargo, introduce un rango amplio de modelos y ofrece unas bases sólidas construidas sobre explicaciones muy intuitivas para comprender cualquier otro algoritmo de Machine Learning.
Este curso fue actualizado y transformado en especialización en 2022.
En la actualidad se trata de una Especialización completa de Machine Learning compuesta por tres cursos:
- Un curso en el que se trata el aprendizaje automático supervisado
- Un curso de modelos un poco más avanzados de Machine Learning en el que se introducen las redes neuronales
- Un tercer curso en que se aborda el aprendizaje no supervisado, los sistemas de recomendación y el aprendizaje por refuerzo
En estos cursos se muestran las tripas de los modelos más sencillos, e incluso llegamos a implementar algunos de ellos desde cero. Así podrás adquirir unas habilidades que no pasan de moda.
Todos los cursos de esta especialización en Machine Learning están compuestos por explicaciones en vídeos cortitos, de no más de 15 minutos, de cada uno de los temas.
Los vídeos están en inglés pero existe la posibilidad de verlo con subtítulos en español.
Finalmente, la evaluación se realiza mediante cuestionarios tipo test y algunas tareas de programación que son calificadas automáticamente.
Tiempo y dinero
Tal vez te estés preguntando cuánto cuesta el curso de Machine Learning por excelencia.
Pues bien, es posible ver el contenido en vídeo con la teoría de manera GRATUITA aunque no podrás acceder a las tareas de programación ni a los cuestionarios de evaluación.
Y, por supuesto, no te darán un certificado cuando completes los cursos.
Para poder acceder al contenido completo de esta especialización en Machine Learning tendrás que pagar 44€ al mes (o $49 al mes).
Y aunque tengas una vida por delante para completarlo, te interesará saber que la gente de Coursera ha estimado que hacen falta unas 95 horas para terminar la especialización completa.
Se trata de unas 24 horas de vídeo y el resto del tiempo se distribuye en lecturas y tareas de programación. Todo ello repartido en 3 cursos, para que no se te haga bola.
El primero y el último curso tienen una duración de 3 semanas y el curso de redes neuronales y modelos de aprendizaje avanzado se puede completar en unas 4 semanas.
De todas maneras, si quieres ir más rápido, sin problema.
Y si quieres ir más despacio, también puedes.
Prerrequisitos
Aunque los conceptos del curso están explicados con ejemplos muy intuitivos para poder comprender las ideas que hay detrás de cada modelo de Machine Learning, para poder seguir el curso es necesario tener una base en matemáticas.
Concretamente, cuanto más sepas de las siguientes cosas, más sencillo te resultará el curso:
- Álgebra lineal y cálculo con matrices y vectores.
Andrew utiliza las operaciones con vectores y matrices durante todo el curso por lo que si no tienes destreza en su manejo tal vez te cueste un poco más al principio.
De todas maneras, en el curso lo han tenido en cuenta y hay una serie de vídeos en los que explican qué hay que saber exactamente.
- Cálculo de derivadas parciales y sumatorios
La idea básica para obtener cada modelo de aprendizaje automático consiste en definir una función de coste que mide el error que está cometiendo dicho modelo y ser capaz de minimizarla.
Para representarla necesitaremos sumatorios y para minimizarla nos harán falta derivadas parciales.
La mayoría de las veces Andrew simplemente hace mención al hecho de que está utilizando derivadas parciales para obtener el resultado y no es necesario saber calcularlas aunque saber hacerlo aporta claridad al desarrollo.
- Teoría de la probabilidad básica
Conceptos como la media y la varianza aparecen a todas horas en el curso de Machine Learning de Coursera. Saber cómo calcularlas y qué representan es clave en el mundo del Aprendizaje Automático.
Además, haber trabajado en alguna ocasión con funciones de densidad de probabilidad y distribuciones gaussianas te hará la vida más fácil a la hora de comprender los conceptos del curso.
Son conceptos que no son complicados y Andrew Ng los explica brevemente durante el curso pero que tal vez si no los has visto nunca se te haga un poco cuesta arriba.
En resumen, el nivel de mates que se presupone para poder seguir el curso es un nivel un poco superior al de un bachillerato de ciencias (más o menos...).

No son conceptos complicados y se introducen, aunque de manera breve y a alto nivel, durante los vídeos pero sí que es verdad que si no eres muy amigo de las mates tal vez es mejor que no empieces por aquí y regreses más tarde a Coursera para entender los entresijos del Aprendizaje Automático.
En cualquier caso, nunca llueve a gusto de todos.
Algunas de las personas que han evaluado el curso se quejan de que el nivel de matemáticas es muy superficial.
Otros dicen que el nivel de matemáticas hace que el curso sea complicado y difícil de seguir.
Así que depende de dónde estés tú con respecto a las matemáticas.
Por otro lado, las evaluaciones de cada módulo se realizan mediante cuestionarios y tareas de programación por lo que tener nociones de programación es de mucha utilidad.
Nada muy ninja, solo lo básico: funciones, bucles, condicionales…
Más sobre esto en el siguiente apartado...
Herramientas
Cada módulo termina con una tarea de programación en la que se aplican los conceptos explicados durante los vídeos de teoría.
Esta tarea es además, junto con los cuestionarios, el medio que se utilizará para evaluar tu rendimiento en el curso.
A diferencia del curso de Machine Learning original en el que se utilizaba Octave, que es una versión de software libre similar a MATLAB, en esta especialización utilizarás Python para el desarrollo de los ejercicios.
Así que prepárate para comenzar a manejar herramientas como TensorFlow.
Estas tareas de programación se realizan en cuadernos de Jupyter que se ejecutan directamente en los servidores de Coursera.
No necesitas instalar nada en tu ordenador.
¿Quién es Andrew Ng?
Andrew Ng lleva la educación y la Inteligencia Artificial en la sangre.
Profesor asociado de la Universidad de Stanford, lideró el grupo de investigación enfocado en Inteligencia Artificial, Aprendizaje Automático y Deep Learning.
De ahí surgió el curso de la plataforma Coursera y también Coursera en sí misma, ya que en 2012, fue Andrew junto con Daphne Koller quienes fundaron la plataforma de e-learning.
Pero Andrew no ha parado desde entonces…
Fue creador del proyecto Google Brain, director del equipo de Inteligencia Artificial en Baidu y es fundador de varias compañías encargadas de promover y divulgar la Inteligencia Artificial.
Para Andrew, la Inteligencia Artificial es la nueva electricidad.
Esto es lo que vas a aprender en el curso de Machine Learning de Coursera
Regresión lineal con una y varias variables
Durante la primera semana del curso de Machine Learning, Andrew Ng hace una declaración de intenciones de lo que será el resto del curso.
Primero introduce los conceptos de manera intuitiva con un ejemplo simplificado, en este caso, la predicción del precio de la vivienda en función de su tamaño.
Está claro que cuanto más grande es una casa, más elevado será su precio de venta.
Al menos, en principio…
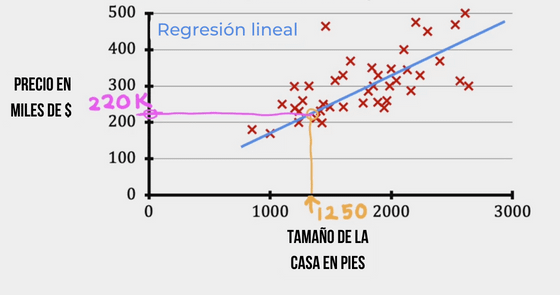
¿Y si aproximamos esa relación entre el tamaño de la casa y su precio de venta con una línea recta?
A partir de este supuesto se introduce la regresión lineal y el concepto de función de coste.
Queremos minimizar la diferencia entre la predicción del modelo de regresión lineal y la observación real en las muestras que tenemos para así poder predecir el precio de nuevas casas a partir de sus tamaños.
Una vez explicado el concepto de función de coste con varias aproximaciones intuitivas, Andrew Ng introduce el algoritmo de descenso de gradiente, cuyo objetivo es minimizar la función de coste de manera iterativa, paso a paso, como si estuvieras en una montaña y quisieras llegar al valle con una venda en los ojos. En cada paso, tantearías con el pie cuál es la dirección a tomar para seguir bajando y darías un pasito en esa dirección. Repetirías el proceso hasta que al tantear el terreno bajo tus pies para dar el siguiente paso no encontraras ninguna dirección cuesta abajo.
Eso significa que ya estás abajo del todo 🙂 (o que igual has llegado a un mínimo local, pero eso ya te lo explica Andrew en el curso)
Regresión logística y regularización
Nuestro objetivo al aplicar regresión lineal era predecir cuánto costaría una casa en función de su tamaño. Predecíamos una cantidad y la aproximábamos por una línea recta.
Después añadimos más características a nuestro modelo (número de habitaciones, estado de la casa...) y en lugar de una línea recta utilizamos un modelo polinómico.
Nuestro objetivo seguía siendo predecir cuánto costaría la casa. Una cantidad.
¿Y si queremos saber si algo sucede o no sucede? ¿O clasificar algo como benigno o maligno, SPAM o no SPAM?
En este caso se utiliza la regresión logística.
Para ello, tuneamos la función de coste y obtenemos una predicción discreta. Un sí o un no.
En este apartado del curso de Machine Learning de Coursera, se introduce el uso de probabilidad para la definición e interpretación de la función de coste en regresión logística.
Además, aparece un clásico en los problemas de aprendizaje supervisado: El sobreajuste (overfitting). Andrew Ng explica por qué sucede el overfitting con modelos basados en regresión polinómica e introduce la regularización para poder paliarlo.

Redes neuronales
Una vez introducidos los modelos más sencillos de predicción y clasificación (regresión lineal y regresión logística), Andrew Ng avanza un paso más presentando las bases de las redes neuronales.
En esta parte del curso de Machine Learning en Coursera, nos enseñan desde cómo representar una red neuronal a cómo implementarla con TensorFlow.
¡Nuestra primera red neuronal!

Consejos a la hora de aplicar Aprendizaje Automático (Diseño de sistemas de Machine Learning)
Bueno, pues ya sabemos implementar los modelos básicos sobre los que se fundamentan los demás.
Estamos preparados para salir al mundo del Aprendizaje Automático.
Analizamos el problema que tenemos que resolver, observamos los datos de los que disponemos y nos ponemos a entrenar un modelo de los que conocemos.
Nada puede salir mal.
O sí…
Si nuestro modelo tiene la misma probabilidad de acierto que lanzar una moneda al aire necesitamos técnicas y consejos para diagnosticarlo.
Que no cunda el pánico porque el curso de Machine Learning de Coursera incluye un capítulo completo sobre cómo aplicar Aprendizaje Automático de manera práctica.
El curso nos ayuda a saber cómo elegir un modelo y los pasos a seguir para mejorarlo si los resultados no son los que esperamos.
Árboles de decisión
Una de las novedades de esta nueva actualización respecto a la primera edición del curso de Machine Learning en Coursera es la introducción a los modelos basados en árboles de decisión.
Estos modelos son muy prácticos y ampliamente usados en la industria.
En esta parte del curso de algoritmos de aprendizaje avanzados, Andrew explica de manera muy intuitiva cómo puede utilizarse un árbol de decisión para realizar predicciones.
Además también se introducen y explican variaciones de estos modelos basados en árboles de decisión como pueden ser los modelos de Random Forest y el archiconocido XGBoost.
Aprendizaje no supervisado
¿Y si no tuviéramos ejemplos de los que aprender?
Para este caso existe el Aprendizaje no supervisado. Los modelos de aprendizaje no supervisado son capaces, por sí solos, de obtener patrones comunes.
Por tanto, una vez ha averiguado los patrones comunes es capaz de agrupar los datos que son similares en clusters.
Este tipo de modelos se utilizan para el análisis de redes sociales o segmentación del mercado.
En este bloque aprendemos el algoritmo de clusterización más típico, K-means.
Andrew Ng nos explica cómo funciona el algoritmo K-means, cómo inicializarlo y qué número de clusters elegir.
Detección de anomalías
Una de las aplicaciones más extendidas de la Inteligencia Artificial es la detección de anomalías. Tal vez, en alguna ocasión hayas recibido una llamada de tu banco preguntándote si has hecho una operación concreta.
No es que te estén vigilando.
Simplemente implementan un algoritmo de detección de anomalías para detectar un uso fraudulento de tu tarjeta. Si el algoritmo detecta que el comportamiento no es el usual, hace saltar las alarmas.
La detección de anomalías también se utiliza en fábricas y líneas de producción para detectar productos defectuosos de manera automática.
En este módulo del curso de Machine Learning, partimos de la base de que disponemos de un número de observaciones elevado y cómo estos datos pueden ser modelados según una distribución gaussiana o normal. Desde aquí, trabajamos la detección de anomalías a partir de la estimación de la densidad de probabilidad.
Andrew Ng presenta el problema a través de un ejemplo sencillo de una fábrica de motores de avión que mide el calor generado por el motor y la intensidad de la vibración. Si estos parámetros no están dentro de lo normal respecto al resto de motores sin fallos, tal vez nos encontremos ante una funcionamiento anómalo que debamos revisar.
Tras presentar la formulación matemática del problema, Andrew introduce el algoritmo de detección de anomalías y nos explica qué principios seguir para la selección de características y para la evaluación de los resultados.
Sistemas recomendadores
La magia de Netflix y cómo sabe que serie nos va a gustar.
El poder de Spotify para sugerirnos nuestra siguiente canción favorita.
Amazon y cómo nos lee la mente para averiguar qué queremos comprar.
Empresas que conocen y aprovechan el potencial de los sistemas recomendadores y que Andrew Ng nos introduce en este capítulo.
Vamos a diseñar el próximo recomendador de películas de Netflix, nuevo y mejorado. (Creo que me estoy vieniendo un poco arriba... 😬)
A partir de este ejemplo, formularemos el problema de los sistemas recomendadores, la función de coste a minimizar y derivaremos el algoritmo más básico de recomendación de películas a partir de filtrado colaborativo.
El filtrado colaborativo utiliza las valoraciones y reseñas que otros usuarios hacen sobre un producto para realizar nuevas recomendaciones.
Si a un grupo de usuarios les suele gustar el mismo tipo de productos, probablemente sea buena idea recomendar algo que a uno de ellos le ha gustado al resto.
Además, en esta parte del último curso de la especialización en Machine Learning, se introduce el filtrado basado en contenido.
Los sistemas de recomendación construidos a partir de filtrado basado en contenido derivan sus resultados de las características que extraen de usuarios y de los productos a recomendar.
A diferencia del filtrado colaborativo, el filtrado basado en contenido no solo se basa en las valoraciones previas de los usuarios sobre los productos sino que incluye características adicionales de usuarios y también de los productos.
Si no te quedan claras las diferencias entre ambos tipos de sistemas de recomendación, no te preocupes. En las tareas de programación tendrás que implementar ambas 🙂
Después de todo esto tal vez no entren ganas de ver un episodio de algo que nos recomiende Netflix 🤩

Aprendizaje por refuerzo
Este apartado sobre aprendizaje por refuerzo también es completamente nuevo respecto a la versión 1.0 del curso de Machine Learning de Stanford en Coursera.
El objetivo de esta lección es que te familiarices con la terminología básica que envuelve a los modelos de aprendizaje por refuerzo.
Aprenderás como estos modelos aplican una u otra política de decisión sobre las acciones que puede realizar un agente basándose en un sistema de recompensas.
Además también se introducen algunos conceptos más avanzados como las ecuaciones de Bellman, la función Q y aprenderás a diseñar una red neuronal DQN (Deep Q-learning Netwoks) en TensorFlow para hacer aterrizar una nave virtual en la Luna 🚀
Diferencias entre el curso de Machine Learning original y la nueva especialización
La nueva especialización en Machine Learning de Stanford en Coursera incluye explicaciones más intuitivas que la versión original del curso.
El objetivo es que los conceptos de alto nivel queden muy claros.
Andrew NG y su equipo se han esforzado para reducir al máximo la necesidad de tener una base matemática muy sólida o unas habilidades de programación avanzadas.
La mayoría de las tareas de programación incluyen gran parte del código en Python necesario para implementar la solución final. La idea es evitar que te bloquees con problemas de programación y puedas centrarte en las ideas fundamentales que se explican en la lección.
Además, también encontrarás algunos ejercicios de programación resueltos que te resultarán muy útiles para comprender cómo resolver problemas de Machine Learning similares.
Procura guardarlos para usarlos como referencia en el futuro 🙂
Respecto al temario, modelos más extendidos en la industria han tomado protagonismo en esta nueva versión. En la especialización se profundiza más en el funcionamiento de modelos basados en árboles de decisión y en los sistemas de recomendación
En definitiva, la nueva especialización es más accesible que el curso original de Machine Learning y ha sido actualizada para aprender a manejarse con herramientas más extendidas en el sector como TensorFlow.
No me voy a andar con rodeos.
Voy a enchufar directamente aquí la definición de aprendizaje automático (o al menos una de ellas) y después te contaré la letra pequeña y otras cosas importantes sobre qué es el machine learning (que es un término cool para decir lo mismo 😜)
Según dijo Arthur Samuel en 1959, el machine learning es el conjunto de técnicas utilizadas para conseguir que un ordenador adquiera una habilidad determinada sin necesidad de haberlo programado explícitamente para realizar esa habilidad.
¡Ojo! porque no vale elegir como habilidad la dominación mundial.

Eso forma parte de la letra pequeña...
El aprendizaje automático y la Inteligencia Artificial
El Machine Learning es solo una parte del campo de la Inteligencia Artificial.
De hecho, el Machine Learning forma parte de las Inteligencias Artificiales Débiles que básicamente consisten en realizar una sola cosa pero hacerla muy bien.
Y, como decía antes, no vale cualquier cosa... Generalmente son cosas que a una persona le llevaría pocos segundos de reflexión llevar a cabo, como reconocer un árbol en una imagen, identificar un mensaje de correo electrónico como SPAM o detectar si un producto presenta defectos de fábrica en una línea de producción.
De hecho, gracias al aprendizaje automático, los ordenadores son capaces de realizar estas tareas mejor que los humanos.
Pero eso no hace que sean inteligentes…

Resumiendo, el Aprendizaje Automático es una forma de Inteligencia Artificial pero la Inteligencia Artificial va mucho más allá del Aprendizaje Automático.
Y aunque muchas veces se usan de manera intercambiable no son lo mismo.
¿De qué va la Inteligencia Artificial?
Vamos a poner un poco en perspectiva dónde queda el Machine Learning dentro del campo de la Inteligencia Artificial.
El aprendizaje automático es una forma de inteligencia ya que le otorga a un ordenador la capacidad de aprender una habilidad y mejorarla a partir de nueva información.
Sin embargo, en la actualidad un ordenador no es capaz de entender la tarea que está aprendiendo y tampoco es capaz de discernir si los datos a partir de los que está aprendiendo son válidos o no.
Una Inteligencia Artificial Fuerte, tipo Terminator, tendría que estar dotada además de inteligencia espacial, emocional, tener la capacidad de comunicarse de manera compleja, poseer inteligencia creativa y además ser capaz de reconocer sus propios intereses y objetivos… entre otras muchas cosas.
Es posible que ahora estés pensando que también conoces personas que no cumplen esos requisitos…
En la actualidad no se conocen Inteligencias Artificiales de este tipo.
De momento podemos dormir tranquilos...

¿Para qué sirve el Machine Learning?
Ahora que las IA tipo Terminator han dejado de acecharnos y nos hemos quedado más tranquilos (yo por lo menos...) voy a contarte para qué sirve el Aprendizaje Automático.
El Machine Learning se ha convertido en el corazón de la Inteligencia Artificial desde que el acceso a grandes cantidades de datos se ha democratizado.
A partir de estos datos, el Aprendizaje Automático es capaz de adquirir una habilidad determinada sin necesidad de que nadie le programe y automatizar una tareas de manera muy eficiente.
Además, este tipo de Inteligencia Artificial ya forma parte de nuestro día a día desde hace algún tiempo.
Por ejemplo, la Inteligencia Artificial ya es capaz de inspeccionar si un producto en una cadena de producción es defectuoso o no, también se emplea en el campo de la medicina para poder asistir a un radiólogo en la detección de lesiones o enfermedades a partir de radiografías o de manera comercial en cualquiera de los asistentes por voz como Alexa o Siri.
¿Cómo funciona el Aprendizaje Automático?
La idea básica detrás de la forma más extendida de Machine Learning consiste en mapear una serie de datos de entrada con una salida determinada a través de un modelo.
En palabras normales, este tipo de Inteligencia Artificial aprende de la misma manera que un niño pequeño.
Cada vez que se cruzan con un perro, sus padres le dicen que eso es un perro.
Cada vez que se cruzan con un gato, le indican que eso es un gato.
En el caso del algoritmo de Machine Learning, en lugar de sacarlo de paseo buscando perros y gatos, le mostraremos muchas fotos de perros y gatos y le diremos cuál es cuál.
Nota: En el caso del ordenador será necesario enseñarle muchas más fotos de perros y gatos que en el caso del niño (por suerte para los padres del niño).
Una vez que hayamos terminado de “educar” a nuestro algoritmo de Machine Learning para ser capaz de diferenciar entre un gato y un perro, podremos mostrarle una foto nueva.
Si todo ha ido bien, nos indicará correctamente de qué animal se trata (perro o gato).
A priori, no sabemos cómo el algoritmo ha aprendido si está ante la imagen de un perro o un gato o cuál es el modelo concreto que utiliza para tomar su decisión.
De momento tampoco nos importa.
Tipos de Machine Learning
He de reconocer que no te he contado toda la verdad.
El caso anterior, en el que enseñábamos a nuestro algoritmo a diferenciar entre perros y gatos, es un caso concreto de Aprendizaje Supervisado, es decir, para obtener el algoritmo o modelo que diferencie entre gatos y perros es necesario pasarle muchos ejemplos con solución de imágenes de gatos y perros.
Sin embargo, no es el único tipo existente aunque sí se trata del más extendido.
Aprendizaje Supervisado
Como hemos visto, en este caso el aprendizaje está supervisado por un adulto.
El algoritmo es capaz de mapear datos de entrada con la salida esperada y utilizar ese aprendizaje sobre entradas que no ha visto anteriormente.
La pega de este tipo de Machine Learning, es que no siempre es fácil conseguir ejemplos con solución de un problema determinado.
Por ejemplo, para el problema concreto de distinguir perros y gatos habría que conseguir miles de imágenes de perros y gatos y etiquetarlas con el animal correspondiente. Esto generalmente tiene que hacerlo una persona.
Y llega a ser muy costoso.
Aprendizaje No Supervisado
Mediante el aprendizaje no supervisado, el algoritmo intenta aprender sin la supervisión de un adulto.
Este tipo de algoritmo suele buscar patrones y características comunes en los datos para agruparlos. Es posible que no sepa qué es un perro y qué es un gato pero es claramente capaz de diferenciar entre uno y otro.
Además, el aprendizaje no supervisado es muy útil en la detección de anomalías, por ejemplo, en una cadena de producción.
Si en dicha cadena de producción hay fundamentalmente piezas bien hechas, el algoritmo será capaz de diferenciar una pieza defectuosa al verla aunque nadie le haya dicho cómo es una pieza mal hecha.
Aprendizaje Reforzado
En el caso de Machine Learning mediante aprendizaje reforzado, el algoritmo aprende mediante recompensas y penalizaciones.
Antes te contaba como unos padres le enseñaban a su hijo a diferenciar entre perros y gatos.
Pues resulta que de tanto enseñarle perros y gatos, el niño se empeña en tener una mascota y sus padres deciden adoptar un cachorro.
Primer problema: Enseñar al perro a hacer sus necesidades en el lugar adecuado.
¿Cómo hacerlo?
Mediante Aprendizaje Reforzado. No se le da ninguna indicación al cachorro. Sin embargo, cuando se comporte según lo esperado se le dará una recompensa y cuando no sea así, se le regañará.
Con el tiempo, el animal aprenderá el comportamiento correcto.
Se trata del clásico aprendizaje basado en prueba y error pero aplicado a Machine Learning.
El Aprendizaje reforzado está basado en conseguir que el algoritmo adquiera la habilidad deseada a través de maximizar las recompensas y minimizar las penalizaciones.
Ejemplos de Machine Learning
Si lo mejor de lo que es capaz el Machine Learning es diferenciar entre perros y gatos estarás pensando que tal vez está un poco sobrevalorado.
¿verdad?
Ahora cambia las imágenes de gatitos por radiografías de personas sanas y de personas con alguna patología concreta. Con el número suficiente de imágenes el aprendizaje automático puede asistir a radiólogos en la detección de enfermedades de una manera menos costosa (aprendizaje supervisado).
Los casos de uso en el campo de visión por ordenador utilizan aprendizaje supervisado para aplicaciones tan variadas como el desbloqueo de dispositivos mediante reconocimiento facial y la detección de otros coches, de peatones y de otros objetos en los primeros prototipos de coches autónomos.
También tenemos el caso de detección de unidades defectuosas en una cadena de producción con el claro aumento de eficiencia en la fábrica.
Este caso de uso podría aplicarse mediante aprendizaje supervisado (si tenemos la suficiente cantidad de imágenes de unidades correctas y unidades defectuosas) o mediante aprendizaje no supervisado (si se puede asegurar que las unidades defectuosas son muy poco frecuentes y pueden ser consideradas como outliers).
Otro campo de aplicación del Aprendizaje Automático que despierta gran interés es el campo del Procesamiento del Lenguaje Natural (NLP por sus siglas en inglés, Natural Language Processing).
Desde la detección de correos de SPAM que incluso es capaz de detectar correos de venta o promociones pasando por la interpretación de la intención de búsqueda del usuario cuando se realiza una consulta en el buscador del navegador o la traducción automática de textos.
Todos ellos son ejemplos de Machine Learning que usamos todos los días sin ni siquiera darnos cuenta.
Además, en el campo empresarial el Aprendizaje Automático está generando beneficios (muchos) gracias a la segmentación de clientes.
Si ofreces a un cliente lo que quiere es más probable que lo compre y además aumenta la probabilidad de que cuando necesite algo vuelva a comprarte a ti.
¿Qué empresa no querría conocer mejor a sus clientes?